 class Stats
class Stats This is a simple stats object
 Stats(int _m = STATS_FAST_ADD)
virtual ~Stats()
int getMode()
void add(DWORD _n, DWORD _s=0)
DWORD median()
DWORD mean()
double meanDbl()
double variance()
double stdDevDbl()
int optimalClassCount()
int getCount()
DWORD minimum()
DWORD maximum()
double midpoint()
int intervalSize()
StatsNode* m_root
StatsNode* m_middle
StatsNode* m_tail
unsigned long m_sum
int m_mode
int m_count
void slow_add(DWORD _n, DWORD _s)
void fast_add(DWORD _n, DWORD _s)
DWORD slow_median()
DWORD fast_median()
double slow_meanDbl()
double fast_meanDbl()
double slow_variance()
double fast_variance()
Stats(int _m = STATS_FAST_ADD)
virtual ~Stats()
int getMode()
void add(DWORD _n, DWORD _s=0)
DWORD median()
DWORD mean()
double meanDbl()
double variance()
double stdDevDbl()
int optimalClassCount()
int getCount()
DWORD minimum()
DWORD maximum()
double midpoint()
int intervalSize()
StatsNode* m_root
StatsNode* m_middle
StatsNode* m_tail
unsigned long m_sum
int m_mode
int m_count
void slow_add(DWORD _n, DWORD _s)
void fast_add(DWORD _n, DWORD _s)
DWORD slow_median()
DWORD fast_median()
double slow_meanDbl()
double fast_meanDbl()
double slow_variance()
double fast_variance()
This is a simple stats object. This package is in the initial open stages. It is designed to do simple statistical caluclations very fast, or to add data to a dataset very fast.
To Do:
- High Priority:
- weighted average: wa=sum(XY)/sum(Y)
- geometric mean: gm=root(n, sum(X))
- average deviation: ad=sum(X-mean(X))/N
- mean absolute deviation: mad=sum(abs(X-mean(X)))/N
- skewness: s=(3*(mean(X)-median(X)))/stddev(X)
- normal deviate(q): nd=(q-mean(X))/stddev(X)
- mean difference: md=sum(X-Y)/N
- difference variation: dv=sum(pow((X-Y)-md(XY), 2))/(N-1)
- std diff dev: sdd=sqrt(dv)
- Medium Priority:
- Cache results of calculations, including makeing calls to quicksort cache results.
- Throw/catch exceptions.
- Implement a mechanism to get a class of arbitrary size. This should return a new Stats object.
- Allow for variant median on odd number of entries.
- Allow for the population variant of std dev and variance.
- Low Priority:
- Mode.
- Deprecate useless functions (like DWORD mean) and rename certain functions (*Dbl).
- Support various datatypes -- DWORD is not enough. One way is to templatize it, unless speed then becomes an issue. If so, consider creating a set of classes similar to this.
- Store data in a better data structure -- see blue book.
- Reorder definitions in this file for better grouping/looking docs.
- Provide some samples in the documentation.
- Turn test* into a Test class/object.
 Stats(int _m = STATS_FAST_ADD)
Stats(int _m = STATS_FAST_ADD)
This creates a new stats object of the requested type.
The regression tests for this function are in test_0()
This destroys a stats object. The regression tests for this function are in test_0()
This will return the stats object mode. The regression tests for this function are in test_1()
This will add a data element to the stats object dataset. The fast_add(...) function simply adds a new node to the head (m_root)
of the datalist and increments the item count. There is no sorting, nor
is there a running sum, etc... However, the most important aspect of
the fast mode is that the m_tail and m_middle pointers are invalid --
only the m_root pointer is used. The slow_add(...) function is much more complex: The regression tests for this function are in test_2() and test_3().
This function returns the median element of the dataset. Note: in both cases, the median is the center element if The regression tests for this function are in test_4() and test_5(). To Do:
This function returns the mean (average) element of the dataset. It
returns a rounded integer representation of the result from: The regression tests for this function are in test_6() and test_7().
This function returns the mean (average) element of the dataset. This is exactly the same as mean(), except is casts the operands to the
final divide to double before doing the division. The regression tests for this function are in test_8() and test_9().
This returns the (population) variance. The regression tests for this function are in test_21() and test_22().
This returns the sample std deviation. To Do:
The regression tests for this function are in test_10() and test_11().
This function will return the "optimal" class count. This is defined by
the smallest This table demonstrates what to expect: The regression tests for this function are in test_12().
returns the number of data elements in this object. The regression tests for this function are in test_13().
This returns the minimal datum in this object. Currently, if the dataset
is empty, this function returns 0. The regression tests for this function are in test_14() and test_15().
This returns the maximal datum in this object. Currently, if the dataset
is empty, this function returns 0. The regression tests for this function are in test_16() and test_17().
This returns the midpoint of the range of this dataset. This is
not the mean or median, it is If there is only 1 element in this dataset, that 1 element is the
midpoint, which is an exception to the above stated formula. If the
dataset is empty, the midpoint claims to be 0. The latter will be
replaced with an exception in the future. The regression tests for this function are in test_18() and test_19().
This function will return the size of the interval based on the
optimal number of classes. This function is heavily based on the
optimalClassCount. With The following table is an example of what to expect: The regression tests for this function are in test_20().
This will add a data element to the stats object dataset. This is for
internal use only, please see void add(DWORD _n);
This will add a data element to the stats object dataset. This is for
internal use only, please see void add(DWORD _n);
This function returns the median element of the dataset. This is for
internal use only, please see DWORD median();
This function returns the median element of the dataset. This is for
internal use only, please see DWORD median();
This function returns the mean (average) element of the dataset. This is
for internal use only, please see double meanDbl();
This function returns the mean (average) element of the dataset. This is
for internal use only, please see double meanDbl();
This returns the sample std deviation. This is for internal use only,
please see double variance();
This returns the sample variance. This is for internal use only,
please see double variance();
The storage of the data in this object is a double linked list, with a
great deal of help by the StatsNode object. This linked list may or may not be ordered depending on the mode of this
object. (see add for more information on this particular issue) The list has a m_root pointer to the head of the list, a m_tail pointer to
the backend of the list, and a m_middle pointer to the median for quicker
(in reality, probably not too much quicker) adds and/or lookups. I'm strongly considering alternate data structures for this object.
virtual ~Stats()
int getMode()
void add(DWORD _n, DWORD _s=0)
_s - This is the (optional) secondary data to add to the object. If
this data is permitted, it is assummed to be 0. When using
paired data, these two data elements cannot be separated, it's
analogous to adding (x,y) to the dataset instead of just x.
DWORD median()
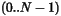 if
if 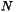 is odd, and it is the center element of elements
is odd, and it is the center element of elements 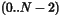 if is
even. ( being the number of elements).
if is
even. ( being the number of elements).
DWORD mean()
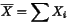
double meanDbl()
double variance()
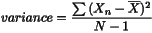
double stdDevDbl()
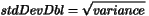
int optimalClassCount()
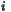 such that
such that 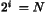 .
.
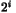
0 0 1
1 1 2
2 1 2
3 2 4
4 2 4
5 3 8
6 3 8
7 3 8
8 3 8
9 4 16
16 4 16
17 5 32
100 7 128
1000 10 1024
10000 14 16384
int getCount()
DWORD minimum()
DWORD maximum()
double midpoint()
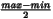 .
.
int intervalSize()
as the number of elements in this dataset, is selected by
optimalClassCount() (based on , see optimalClassCount() for more
details). The interval size is then the following:
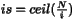
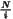
0 0 1 0
1 1 2 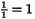
2 1 2 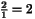
3 2 4 
4 2 4 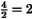
5 3 8 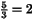
6 3 8 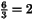
7 3 8 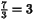
8 3 8 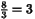
9 4 16 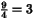
16 4 16 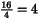
17 5 32 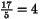
100 7 128 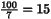
1000 10 1024 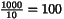
10000 14 16384 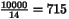
void slow_add(DWORD _n, DWORD _s)
_s - This is the secondary data to add to the object.
void fast_add(DWORD _n, DWORD _s)
_n - This is the secondary data to add to the object.
DWORD slow_median()
DWORD fast_median()
double slow_meanDbl()
double fast_meanDbl()
double slow_variance()
double fast_variance()
StatsNode* m_root
StatsNode* m_middle
StatsNode* m_tail
unsigned long m_sum
int m_mode
int m_count
alphabetic index hierarchy of classes
generated by doc++